Overview
Multi-threading is the ability for an application to perform more than one execution simultaneously. When used properly, it can greatly improve the responsiveness and efficiency of an application. However, multi-threading in Windows was quite difficult and error-prone. But with the support from various .NET base classes in the System.Threading namespace, it is now a relatively easy task. And since ASP.NET pages can be created with any .NET languages, we can build some ASP.NET pages that feature multi-threading. This article is the first of the series of 4. I will demonstrate the use of threading in web applications by implementing a simply search engine. The following 3 articles in the series will be a Port Scanner, a Reverse DNS and a Web Hammer respectively.
Description
This is a very simple search engine. Its been developed in VS.NET (as an editor), and the final release of the .NET Framework SDK. The search engine consists of only 2 files. First is the search.aspx, which contains the form and a listing control. The form allows us to enter a keyword to search for, and a list of URLs to search on. Then there is the search.aspx.cs, which is a code-behind file containing the code that does the searching. When you hit the search button, a method in the code-behind file will be called. It will then create a thread for each searching page. All the threads are started as soon as they are created. All of them will be independently connect to their assigned web page, get their content, and search for the keyword. After all the threads are started, the method will wait for all of them to return before the method itself returns to the caller (the search.aspx).
Lets first look at the search.aspx:
<%@ Page Language="C#" AutoEventWireUp="false" Inherits="MultiThreadedWebApp.SearchEngine" Src="search.aspx.cs" %>
<script language="c#" runat="server">
protected void search(Object sender, EventArgs e) {
if ( SearchWebSites( keyword.Text, urls.Text ) ) {
info.Text = "Searched <font color=\"red\">" + SearchResults.Count + "</font> web page(s) ";
info.Text += "on the keyword <font color=\"red\">\"" + keyword.Text + "</font>\". ";
info.Text += "Total search time was <font color=\"red\">" + timeSpent + "</font>";
SearchForm.Visible = false;
ResultList.DataSource = SearchResults;
ResultList.DataBind();
}
}
</script>
<html>
<head>
<title>Multi-threaded Search Engine</title>
<style>.BodyText { font-family: verdana; font-size: 12px; color: 333333; } </style>
</head>
<body>
<asp:label id="info" class="BodyText" text="URL of the web sites to search, one url per line."
runat="server" /><br />
<asp:Repeater id="ResultList" runat="server">
<HeaderTemplate>
<table class="BodyText" border="0" cellpadding="3" cellspacing="3">
<tr>
<td><b>Found</b></td>
<td><b>Web Page Title</b></td>
<td><b>Web Page URL</b></td>
<td><b>Searched Time</b></td>
</tr>
</HeaderTemplate>
<ItemTemplate>
<tr>
<td><%# DataBinder.Eval(Container.DataItem, "instanceCount") %></td>
<td><%# DataBinder.Eval(Container.DataItem, "pageTitle") %></td>
<td><%# DataBinder.Eval(Container.DataItem, "pageURL") %></td>
<td><%# DataBinder.Eval(Container.DataItem, "timeSpent") %></td>
</tr>
</ItemTemplate>
<FooterTemplate>
</table>
</FooterTemplate>
</asp:Repeater>
<form id="SearchForm" runat = "server" >
<table class="BodyText">
<tr>
<td>keyword:</td>
<td><asp:textbox class="BodyText" text="news" id="keyword" runat="server" /></td>
</tr>
<tr>
<td valign="top">urls:</td>
<td><asp:textbox class="BodyText" text="" id="urls" rows="10" columns="30" textmode="MultiLine"
runat="server" /></td>
</tr>
<tr><td align="right" colspan="2">
<asp:button class="BodyText" text="search!" type="submit" onclick="search" runat="server" ID="Button1"/>
</td></tr>
</table>
</form>
</body>
</html>
This page starts by declaring that it inherits from the class MultiThreadedWebApp.SearchEngine, which is contained in the search.aspx.cs file. It has a method, which will be called when we hit the search button. Then theres a repeater control. Repeater control is a powerful Listing Control ASP.NET offers. More information about it can be found in the MSDN Library at:
http://msdn.microsoft.com/library/default.asp?url=/library/en-us/cpgenref/html/cpconrepeaterwebcontrol.asp?frame=true.
Finally, theres the form that allows us to enter the keyword and URLs. When we hit the search button, the method SearchWebSite() in the code-behind file will be called. If the search succeeds, we change the text in the label control to some other text summarizing the search. We also hide the form, and bind the SearchResults object of type ArrayList to the repeater control.
Now, lets see how the search.aspx.cs does the searching:
using
System;
using System.IO;
using System.Net;
using System.Web;
using System.Web.UI;
using System.Text;
using System.Text.RegularExpressions;
using System.Collections;
using System.Threading;
/// <summary>
/// The namespace that contains the 2 classes for the search engine.
/// </summary>
namespace MultiThreadedWebApp
{
/// <summary>
/// The class that inherits the System.Web.UI.Page class.
/// It provides methods and properties for the ASPX page.
/// </summary>
public class SearchEngine : Page
{
// private member fields.
private ArrayList _pages;
private TimeSpan _timeSpent;
/// <summary>
/// Returns an ArrayList of WebPage objects,
/// which contains the search results information.
/// </summary>
public ArrayList SearchResults
{
get { return _pages; }
}
/// <summary>
/// A TimeSpan object. It lets us know how long was the entire search.
/// </summary>
public TimeSpan timeSpent
{
get { return _timeSpent; }
}
/// <summary>
/// Start searching the web sites.
/// </summary>
/// <param name="keyword">The keyword to search for.</param>
/// <param name="pURLs">List of URLs, seperated by the \n character.</param>
/// <returns></returns>
public bool SearchWebSites(string keyword, string pURLs)
{
// start the timer
DateTime lStarted = DateTime.Now;
_pages = new ArrayList();
// split the urls string to an array
string[] lURLs = pURLs.Split('\n');
int lIdx;
WebPage wp;
// create the Thread array
Thread[] t = new Thread[ lURLs.Length ];
for ( lIdx = 0; lIdx < lURLs.Length; lIdx ++ )
{
// create a WebPage object for each url
wp = new WebPage(keyword, lURLs[lIdx]);
// add it to the _pages ArrayList
_pages.Add( wp );
// pass the search() method of the new WebPage object
// to the ThreadStart object. Then pass the ThreadStart
// object to the Thread object.
t[lIdx] = new Thread( new ThreadStart( wp.search ) );
// start the Thread object, which executes the search().
t[lIdx].Start();
}
for ( lIdx = 0; lIdx < _pages.Count; lIdx ++ )
{
// waiting for all the Threads to finish.
t[lIdx].Join();
}
// stop the timer.
_timeSpent = DateTime.Now.Subtract( lStarted );
return true;
}
}
/// <summary>
/// The class that contains information for each searched web page.
/// </summary>
public class WebPage
{
// private member fields.
private int _instanceCount;
private string _pageURL;
private string _pageTitle;
private string _keyword;
private TimeSpan _timeSpent;
/// <summary>
/// A TimeSpan object. It lets us know how long was the page search.
/// </summary>
public TimeSpan timeSpent
{
get { return _timeSpent; }
}
/// <summary>
/// How many times the search keyword appears on the page.
/// </summary>
public int instanceCount
{
get { return _instanceCount; }
}
/// <summary>
/// The URL of the search page
/// </summary>
public string pageURL
{
get { return _pageURL; }
}
/// <summary>
/// The title of the search page
/// </summary>
public string pageTitle
{
get { return _pageTitle; }
}
public WebPage() {}
/// <summary>
/// A parameterized constructor of the WebPage class.
/// </summary>
/// <param name="keyword">The keyword to search for.</param>
/// <param name="pageURL">The URL to connect to.</param>
public WebPage(string keyword, string pageURL)
{
_keyword = keyword;
_pageURL = pageURL;
}
/// <summary>
/// This method connects to the searching page, and retrieve the page content.
/// It then passes the content to various private methods to perform other operations.
/// </summary>
public void search()
{
// start timing it
DateTime lStarted = DateTime.Now;
// create the WebRequest
WebRequest webreq = WebRequest.Create( _pageURL );
// connect to the page, and get its response
WebResponse webresp = webreq.GetResponse();
// wrap the response stream to a stream reader
StreamReader sr = new StreamReader( webresp.GetResponseStream(), Encoding.ASCII );
StringBuilder sb = new StringBuilder();
string line;
while ( ( line = sr.ReadLine()) != null )
{
// append each line the server sends, to the string builder
sb.Append(line);
}
sr.Close();
string pageCode = sb.ToString();
// get the page title
_pageTitle = getPageTitle( pageCode );
// get the amount of time the keyword appeared on the page
_instanceCount = countInstance( getPureContent( pageCode ) );
// stop the timer
_timeSpent = DateTime.Now.Subtract( lStarted );
}
// this method uses the regular expression to match the keyword.
// it then count the matches to find out how many times the keyword appeared on the page.
private int countInstance(string str)
{
string lPattern = "(" + _keyword + ")";
int count = 0;
Regex rx = new Regex(lPattern, RegexOptions.IgnoreCase | RegexOptions.Compiled );
StringBuilder sb = new StringBuilder();
Match mt;
for ( mt = rx.Match(str); mt.Success; mt = mt.NextMatch() )
count ++ ;
return count;
}
// this method uses the regular expression to match the pattern that represent all
// string enclosed between ">" and "<". It removes all the HTML tags,
// and only returns the HTML decoded content string.
private string getPureContent(string str)
{
string lPattern = ">(?:(?<c>[^<]+))";
Regex rx = new Regex(lPattern, RegexOptions.IgnoreCase | RegexOptions.Compiled );
StringBuilder sb = new StringBuilder();
Match mt;
for ( mt = rx.Match(str); mt.Success; mt = mt.NextMatch() )
{
sb.Append( HttpUtility.HtmlDecode( mt.Groups["c"].ToString() ) );
sb.Append( " " );
}
return sb.ToString();
}
// this method uses the regular expression to match the pattern that represent the
// HTML Title tag of the page. It only returns the first match, and ignores the rest.
private string getPageTitle(string str)
{
string lTitle = "";
string lPattern = "(?:<\\s*title\\s*>(?<t>[^<]+))";
Regex rx = new Regex(lPattern, RegexOptions.IgnoreCase | RegexOptions.Compiled );
Match mt = rx.Match(str);
if ( mt.Success )
try
{
lTitle = mt.Groups["t"].Value.ToString();
}
catch
{
lTitle = "";
}
else
lTitle = "";
return lTitle;
}
}
}
This code-behind file contains the namespace MultiThreadedWebApp. And there are 2 classes in this namespace. The first is the SearchEngine class, which inherits the System.Web.UI.Page class. This SearchEngine class is also the class that the search.aspx diverts from. It creates, starts and manages the threads for each searching page. Then there is another class WebPage, which contains information about each individual web page. This class connects to the web page, get its content and do the searching.
The SearchEngine class has 2 properties: the SearchResults of type ArrayList containing a list of WebPage objects, and a TimeSpan object timeSpent containing the time that the search took. The class only has one method, which is SearchWebSites(). The method first splits the string pURLs into an array of string. pURLs contains a list of URLs separated by new line characters. It then creates a WebPage object for each URL, and adds the object to the private _pages ArrayList, which is exposed by the property SearchResults. After the WebPage object is added to _pages, it creates a ThreadStart object by passing it the address of the search() method of the WebPage object. A ThreadStart object is basically a delegate, which holds a reference to the method that we like to be executed by a thread. The method that passes to the ThreadStart must not have any parameters and must not return anything. We can then create a Thread object from the ThreadStart object. And as soon as we have created the Thread object, we call its Start() method, which executes the search() method in the WebPage object. After we have started all the threads, we will wait for all of them to return. We loop through the Thread array, and call the Join() method of each thread. Thread.Join() is an overloaded method with 3 different signatures. But we are using the one with no parameters, which just wait for the thread to return infinitely. More information about Threads in .NET can be found in the MSDN Library at:
http://msdn.microsoft.com/library/default.asp?url=/library/en-us/cpguide/html/cpconthreading.asp?frame=true
The WebPage class is where an individual page get connected and searched. Its search() method first create a WebRequest object to connect and get the responded content from the searching page. It then calls various private method to fill the private member fields: _timeSpent, _instanceCount and _pageTitle, which are exposed by the public properties: timeSpent, instanceCount and pageTitle respectively. The private method countInstance() will take a string containing the pure content without any HTML tags. It uses regular expression to match the keyword from the content, and count the number of matches to determine how many times the keyword has appeared on the page. The private method getPureContent() also uses regular expression to remove all the HTML tags. It returns the pure content of the page. The private method getPageTitle() method also uses regular expression to extract the title enclosed in the first HTML title tag. Some examples of regular expression can be found in the MSDN library at:
http://msdn.microsoft.com/library/default.asp?url=/library/en-us/cpguide/html/cpconregularexpressionexamples.asp?frame=true
Search Engine in Action
Run the search.aspx. Enter a keyword and a list of URLs. Then hit search!

The search results are listed by the repeater control, which generates the HTML table etc. And the form is set to not visible, which just didnt get send to the browser.
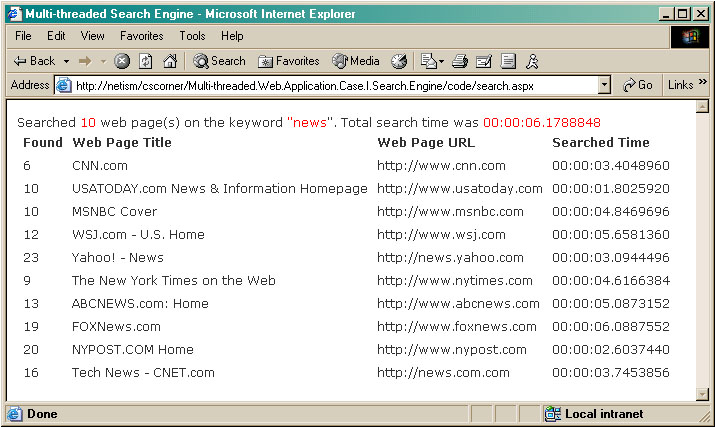
As you can see from the result, the total time was just around 6 seconds, which was pretty much around the time the longest individual search took (the foxnews). Now imagine if the application does not have the multi-threading capability, and needs to search the web pages one by one. The total time would have been the sum of all individual searches, which would be close to 40 seconds!
Conclusion
The search engine demonstrated is probably the simplest one you can build. But you should get the idea of how you can incorporate multi-threading in a web based search engine, or web applications in general. But over use of threads could harm the applications too. For instance, if you are trying to flip the web upside down searching thousands of web pages, with a thread handling each page. Then you might run out of memory to create the threads! Even if you do have enough memory, the CPU might be busy for a good few minutes just switching around and managing all the thread executions, before anyone of them would even have a chance to get connected to the page. In such case, you might want to incorporate a thread pool. More information about thread pooling can be found in the MSDN Library at:
http://msdn.microsoft.com/library/default.asp?url=/library/en-us/cpguide/html/cpconthreadpooling.asp?frame=true