Inserting Data Using SELECT with INSERT
All of the preceding INSERT statements insert a single row into a table. If you want to insert more than one row at a time, you must have a source where those rows already exist. That source is typically another table, or a join between two or more other tables. In this form of the INSERT statement, you use a subquery to determine the rows of data for insertion. The subquery's result set becomes the set of rows to be inserted. The number of columns in the subquery's result set must match the number of columns in the table, and the columns must have compatible datatypes. In this first example, you create a table to keep track of addresses.
create table address_list
(name varchar(20) not null,
address varchar(40) not null,
city varchar(20) not null,
state char(2) )
This command did not return data, and it did not return any rows. This table has four character fields, so any SELECT statement you use to populate it must return four character columns. Here is an example:
insert into address_list
select stor_name, stor_address, city, state
from stores
(6 row(s) affected)
Unlike the subqueries you read about in yesterday's lesson, there are no parentheses around the subquery used with an INSERT statement. The column names used in the subquery are ignored; the table already has column names associated with each field.
You can execute another INSERT statement to add more rows to your address_list table. Suppose you want to add names and addresses from the author's name. Instead of a single name, the authors table has a first name column (author_fname) and a last name column (author_lname). The address_list table is expecting just a single value for its name column, so you can concatenate the last and first names. You can include a comma and space in the concatenated result. For example:
insert into address_list
select author_lname + ', ' + author_fname, address, city, state
from authors
(23 row(s) affected)
In this example, the concatenated last and first name fields is longer than the width of the name column in the new address_list table. SQL Server does not return an error message when you execute this statement. When trying to insert a character string of length L1 into a column defined with maximum length L2, if L1 is greater than L2, SQL Server only inserts the first L2 characters into the table. Take a look at the values in the address_list table:

select * from address_list
In this last example you create a table to keep track of the names of all the publishers and titles of all the books each publisher has published.
create table publisher_list
(pub_name varchar(40) NULL,
title varchar(80) NULL)
In order to populate this table, you need to join the publishers and titles tables. You should make it an outer join so those publishers who do not currently have any books published are included.
insert into publisher_list
select pub_name, title
from publishers left outer join titles
on publishers.pub_id = titles.pub_id
Inserting Data Using Stored Procedures
SQL Server has one more option for inserting rows into a table. If a stored procedure returns a single result set and you know the number and type of columns that the result set contains, you can INSERT into a table using the results returned when calling that stored procedure. You can create a table to hold the results of running this procedure, and INSERT a row into this table at regular intervals. With the latter, you can monitor the table's growth over time. Take a look at the output of the sp_spaceused procedure (note that your results may vary slightly):
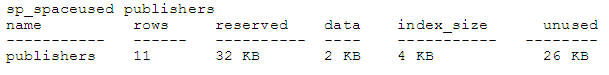
This procedure returns six columns, which are all character strings. Although it looks like the second column is number, it really isn't. The way you could determine the type is to either examine the code for the sp_spaceused stored procedure, or to try to create the table with an integer column. Notice the error message you get when you try to insert a row. The following table should be able to hold the results:
create table space_usage
(table_name varchar(30) not null,
rows varchar(9),
reserved varchar(10),
data varchar(10),
index_size varchar(10),
unused varchar(10) )
To insert into this table you can execute the stored procedure sp_spaceused:
insert into space_usage
execute sp_spaceused publishers
You must make sure that if the stored procedure returns more than one result set, all the results must have the same number of columns and return the same type of data in the corresponding columns. One very nice extension to this capability to insert rows from a stored procedure is the capability to insert rows from a remote stored procedure. If you have a procedure on a remote server that selects all rows from a table, you can execute that procedure to copy all the rows from the remote server to the local one. You must specify the following in your remote procedure call to run a remote procedure:
- Server name
- Database name
- Procedure owner name
- Procedure name
For example, if you had a SQL Server named Wildlife with a database named Water, a procedure named Fish, and an owner of dbo, you could run the following query:
insert into local_table
execute remote_Wildlife.Water.dbo.Swim
There are a few additional considerations when inserting data into a table with an identity column.
Updating with SQL UPDATE
The second data modification statement you look at is the UPDATE statement, which allows you to change the value of columns within an existing row.
UPDATE SQL Statement
Here is basic syntax for UPDATE statement:
UPDATE {table_name | view_name}
SET column_name1 = {expression1 | NULL | (select_statement)}
[, column_name2 = {expression2 | NULL | (select_statement)}...]
[WHERE search_conditions]
The SET clause, with which you specify the columns to be updated, is the part of the statement that is new. The following update statement changes the ytd_sales (year-to-date sales) column in the titles table to 0 for every row. An example of what you might want to do at the start of every year follows:
update titles
set ytd_sales = 0
(18 row(s) affected)
Without a WHERE clause, this statement changes the value of the ytd_sales column to 0 in every row in the table. The following example updates the city column for the publisher Godel Publishing:
update publishers
set city = 'New York'
where pub_name = 'Godel Publishing'
An UPDATE statement can make the new value in the column dependent on the original value. The following example changes the price of all programming books to 10 percent less than the current price:
update titles
set price = price * 0.90
where type = 'programming'
An UPDATE statement can change more than one column. The word SET only occurs once, and the different columns to be changed are separated by commas. The following update statement increases the price of all popular computing books by 20 percent and appends the string '(price increase)' to the notes field of the same rows.
update titles
set price = price * 1.2, notes = notes + ' (price increase)'
where type = 'popular_comp'
UPDATE Using a Lookup Table
A single UPDATE statement can only change rows from a single table. However, SQL Server does allow you to include another table in your UPDATE statement to be used as a lookup table. The lookup table usually appears in a subquery. The subquery can appear in either the WHERE clause or the SET clause of the UPDATE statement. In the next example, change the publisher of all business books to Godel Publishing.
update titles
set pub_id =
(select pub_id from publishers
where pub_name = 'Godel Publishing')
where type = 'business'
(4 row(s) affected)
The publisher name only appears in the publishers table, but it is the titles table that needs to be modified. The subquery accesses the publishers table and returns the publisher ID for Godel Publishing. This value is used as the new value in the pub_id column of titles. Transact-SQL has an extension that allows you to write UPDATE statements using a FROM clause containing multiple tables. This makes the UPDATE appear as a join operation, although only one table is having rows modified. The functionality provided is the same as that used for subqueries; the second table is used only as a lookup table. The following examples show how the previous UPDATE statement can be rewritten using multiple tables in a FROM clause:
update titles
set pub_id = publishers.pub_id
from titles, publishers
where type = 'business'
and publishers.pub_name = 'Godel Publishing'
The choice of whether to use the subquery method or the join method depends mainly upon personal preference. Just as in the DELETE statement, the subquery method seems much clearer regarding which table is modified, what pub_id's new value will be, and what rows are changing. You should also remember that the join method is non-ANSI standard. There are also some UDPATE statements that are more complicated to write using the join method. One such case is if the UPDATE statement uses subqueries for both the SET clause and the WHERE clause. This next example changes the publisher of all programming books published by Godel Publishing to John Godel.
update titles
set pub_id =
(select pub_id from publishers
where pub_name = 'John Godel')
where type = 'programming'and pub_id =
(select pub_id from publishers
where pub_name = 'Godel Publishing')
(4 row(s) affected)
Again, the publisher name only appears in the publishers table, but it is the titles table that needs to be modified. The first subquery accesses the publishers table and returns the publisher ID for John Godel. This pub_id value is used as the new value in the pub_id column of titles.
The second subquery accesses the publishers table again, to return the pub_id value for Godel Publishing. This pub_id is used to determine which rows in the titles table need to be updated. Because the publishers table would need to appear twice--once for determining the new value of pub_id and once for determining the pub_id of the rows to be changed--this UPDATE statement would be much more difficult to write using the join method.
continue article