GROUP BY basics
The GROUP BY clause is typically used to combine database records with identical values in a specified field into a single record, usually for the purposes of calculating some sort of aggregate function. The syntax is remarkably similar to the ORDER BY clause.
SELECT ... GROUP BY column_name
While the syntax is simple, the reality is more complex. Each of the database fields involved in the SELECT statement must either be operated on by an aggregate function or otherwise reduced to a single value for all members of the records creating a group.
Counting all of the employees of a large corporation using GROUP BY on the office_location field would work and so would simple returning the values of office_location after grouping on that field. Selecting the names of those individual employees using GROUP BY would not work because the names for everyone in a single office_location group do not reduce to a single value. There are ways to combine queries to create that sort of a result, but we aren't quite there yet. To add another layer of complexity, you can group on more than one column, just like with the ORDER BY clause.
Another problem with GROUP BY is the behavior of null values. When a column of data is grouped, null values count just like any other value -- and thus all of the "NULLs" are put in one group for the purposes of aggregate functions. This is actually a remarkably sensible way for the underlying SQL algorithms to work and should seem intuitive, but it is important to remember that you'll get one more aggregate value than you expect if the database contains null values unless you somehow filter out those null values.
GROUP BY in action
Let's revisit a query I talked about a couple weeks ago -- generating a sales report broken down by a particular employee:
SELECT SUM(SalesAmount) WHERE EmployeeID=3
which, given the following table of data:
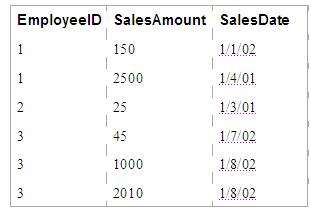
These would return a value of $3,055. This sort of query could be useful in a drill-down or detail report, but it is much more likely that a sales manager would ask for the total sales for all of their employees. We could write a separate SQL statement for each, but it should now be obvious to you that the GROUP BY clause would be much more useful for this scenario. Given the same data set, we can use this SQL statement:
SELECT EmployeeID, SUM(SalesAmount) GROUP BY EmployeeID
this would return the result set
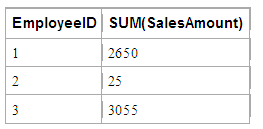
Note that I selected both the aggregated sum of the SalesAmount field for each employee, but also the EmployeeID field. This is allowed since the EmployeeID is identical for each set of records in a group. We couldn't SELECT the SalesDate field since the records in each group consist of different values for the SalesDate field. Of course if we grouped the records by SalesDate to create a daily report.
SELECT SalesDate, SUM(SalesAmount) GROUP BY SalesDate
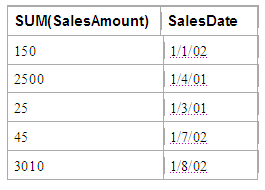
we can SELECT the SalesDate field which is identical for each of the records in a group, but now we cannot SELECT the EmployeeID since each day's sales will typically be made up of more than one employee's sales.
ORDER BY
Many web application developers don't know much about SQL when they start, and they end up spending a lot of time reinventing the wheel when SQL already provides them with an idling Ferrari! The functions and aggregate functions we've talked about the past two weeks certainly fit into that category, as does this week's topic -- ordering data for display using SQL.
Basics of ordering
It's not unusual to be asked to sort data by one or more criteria -- maybe employees by their annual sales, students by their grades, or albums by their release date. The syntax is:
SELECT ... ORDER BY column_name
So to sort all BOOKs in a books table by their original release date, you could use the SQL statement:
SELECT Title, Author, Year FROM MusicCollection ORDER BY Year
and the result would look something like:

As you can see, implementing a sort using the ORDER BY clause is simple. Changing the default ascending sort order into descending is as simple as adding the DESC keyword and multiple sort columns can easily be specified simply by appending them to the list:
ORDER BY column_name_1, column_name_2 DESC
This example for sort the data in ascending order based on the first column name and further sort duplicates using the second column name in descending order. This process can be extending to as many columns of sorting as your database can handle.
Fundamentals of ORDER BY
Each database has its own rules about sorting. Some have a single strategy. Some require a certain strategy to be selected when the database is created or when the database server is installed. Changing the behavior of any one of them is non-trivial. Understanding the various options, however, is the first step. There are two broad approaches:
- Dictionary order -- where sorts are performed A-Z followed by 0-9
- Binary order -- where the underlying values of the character set (the language of the application) are sorted numberally. It sounds simple so far, right? But let's think about dictionary order for a moment. Clearly all A-Z sorts are not created equal; in fact, here are a few complicating factors:
- Case sensitivity -- does A=a?
- Accent sensitivity -- does A=Å?
- Linguistic practice -- how does that culture sort unusual situations (e.g., Scandinavian sort settings)
And of course there are the obligatory combinations of all of these factors. If you work purely in the A-Z, 0-9 world, the only real issue is case sensitivity. But for any international applications, make sure you know how your database will really sort the contents of the data fields.
And there's one final complication to note -- what about NULLs? We haven't talked much about NULL yet, but will spend considerable time on it as we move forward. NULLs are the content of any database field that contains no data.
Where in the sort order do they rank? Fortunately this is a pretty easy answer -- at the beginning. NULLs have no value. Consequently, A-Z and 0-9 are certainly greater than NULL value. Therefore as we sort through the data, NULLs will come out first.
continue article