Index In MongoDB - Part Five
- Introduction to MongoDB - Part One
- Insert, Update and Delete Document in MongoDB - Part Two
- Query On Stored Data In MongoDB - Part Three
- Advance Query Search On MongoDB - Day Four
In the previous article, we have discussed issues related to the data search or query procedure in MongoDB. In the data searching process, performance is one of the key measures. Since there is a collection of about 100 million pieces of data and we need to search some data from that collection then it might possible there are some delays for obtaining the final results. In this scenario, Index is the one of the key parts for increasing the performance of the searching data. In the database structure, index is a type of data structure which defines the columns or fieldnames in the database table or collections to increase the data retrieval process. Actually, an index is small copy of the database table or collections sorted by the key values which helps the database system to return the result at a faster speed.
So, just like others database software, MongoDB also supports Index structure concept. We can create or use indexes in any MongoDB collections. In MongoDB, there are several types of indexes which can be created on any collection. So, choosing the proper type of indexes for any collections is the main key part of the database structures. In this article, we will discuss them one by one.
Compound Index
Compound Index is the one of the most commonly-used and popular indexes in the MongoDB database. Compound index always keeps the values of all fields in a sorted order so that searching documents can be done as per the index key in a much faster way. This type of index can work only when we use sort() in the query command like below,
- db.users.find().sort({“age” : 1, “city”:1})
This command actually sorts the results on “age” and then on “city”. But a string sorting by “city” is not so helpful as per the performance. So, for achieving performance optimization, we need to make an index on the user's collection of age and city field. The syntax of creating an index is as below,
- db.users.ensureIndex({“age” : 1, “city”:1})
This type of index is normally known as compound index. It is very helpful index for running those queries which contain multiple field names in the conditions. Compound index can be created on a single field or a multiple field. But one thing we need to remember is that speed always depends on the query return data; i.e., how many records the result will return. If there is a large number of data, then the speed will be decreased for returning the data. If at any time, there are more than 32 MB of data returned, the MongoDB will just throw an error. When we create a collection, MongoDB always creates one index on the field of “_id” at the time of creating the collections. But we can create multiple indexes on the single collections but need to remember that that key combination must be unique in case of that particular collection. If you try to create a new index with the same key collections, then MongoDB throws a message that “Index already exists”.
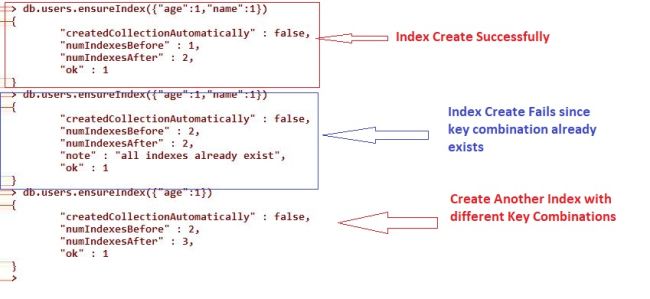
Index Cardinality
Cardinality refers to what number of distinct values there are for a square measure for a field during an assortment. Some fields, like "gender" or "newsletter opt-out", may solely have 2 attainable values, which is taken into account as a really low cardinality. Others, like "username" or "email", might have a novel worth for each document within the assortment, that is high cardinality. Still, others fall somewhere in between, like "age" or "zip code". In general, the larger the cardinality of a field, the bigger is the amount of useful AN indexes on its field. This is often a result of the index that can quickly slim the search area to a way smaller result set. For a coffee cardinality field, AN index typically cannot eliminate as several attainable matches.
For example, suppose we have a tendency to had AN index on "gender" and were searching for ladies named Susan. we have a tendency to may solely slim down the result area by some five hundredths before referring to individual documents to seem up "name". Conversely, if we have a tendency to indexed by "name", we have a tendency to may directly slim down our result set to the little fraction of users named Susan then we have a tendency to may talk over with those documents to ascertain the gender. As a rule of thumb, attempt to produce indexes on high-cardinality keys or a minimum of place high cardinality keys initial in compound indexes (before low-cardinality keys).
Explain()
In MongoDB, explain() offers you plenty of knowledge concerning your queries. It is one in every of the foremost necessary diagnostic tools there's for slow queries. you'll be able to conclude which indexes square measure being employed and the way by viewing a query to justify. For any question, you can add a decision to explain() at the top (the method you'd add a sort() or limit(), howev,er explain() should be the last call). There square measure 2 kinds of explain() output that you’ll see most commonly: indexed and non-indexed queries. Special index varieties might produce slightly completely different question plans, but most fields ought to be similar. Also, sharding returns a conglomerate to explain(), because it runs the question on multiple servers. To use explain(), check the below command and results,
- db.users.find({"age" : 42}).explain()

The explain() technique has one optional parameter referred to as verbose that settle for string type value. Specifies the expressive style mode for the justify output. The mode affects the behavior of explain() and determines the quantity of data to come back. The attainable modes are: "queryPlanner", "executionStats", and "allPlansExecution". The default mode is "queryPlanner". For backwards compatibility with earlier versions of explain(), MongoDB interprets true as "allPlansExecution" and false as "queryPlanner". This explain() returns the below types of data or information after execution,
- queryPlanner, that details the arrange selected by the question optimizer and lists the rejected plans;
- executionStats, that details the execution of the winning to arrange and also the rejected plans; and
- serverInfo, that provides info on the MongoDB instance.
Hint()
If you discover that MongoDB is mistreatment totally different indexes than you would like it to for a query, you can force it to use an exact index by mistreatment hint(). as an example, if you would like to create sure MongoDB uses the one, "age" : 1} index on the previous query, you could say the following,
- db.users.find().hint( { age: 1 } )

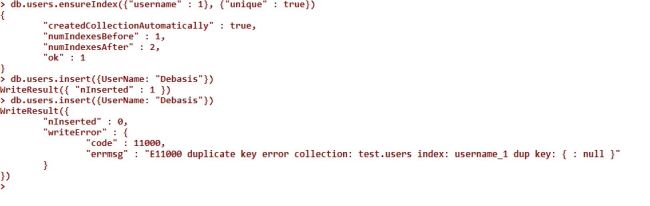
Unique indexes guarantee that every worth can seem at the most once within the index. For example, if you would like to form certain two documents will have constant worth within the "username" key, you'll produce a singular index,
- db.users.ensureIndex({"username" : 1}, {"unique" : true})
If you check the gathering, you’ll see that solely the primary "Debasis" was kept. Throwing duplicate key exceptions isn't terribly economical, therefore use the distinctive constraint for the occasional duplicate, to not separate jillions of duplicates a second.
A unique index that you simply familiar most likely already conversant in is that the index on "_id", which is mechanically produced whenever you create a set. this can be a traditional distinctive index (aside from the very fact that it can't be born as different distinctive indexes will be). If a key doesn't exist, the index stores its worth as null for that document. This means that if you produce a singular index and take a look at to insert more than one document that's missing the indexed field, the inserts will fail as a result of you have already got a document with a price of null.
In some cases, a data won’t be indexed. Index buckets are of a restricted size and if an index entry exceeds it, it simply won’t be enclosed within the index. this may cause confusion because it makes a document “invisible” to queries that use the index. All fields should be smaller than 1024 bytes to be enclosed in AN index. MongoDB doesn't come back any type of error or warning if a document’s fields can't be indexed because of size. this suggests that keys longer than 8 KB won't be subject to the distinctive index constraints: you'll insert identical eight-kilobyte strings, for instance.
Sparse Index
As mentioned in the associate earlier section, unique indexes count null as a value, thus you can't have a novel index with over one document missing the key. However, there are lots of cases wherever you'll need the distinctive index to be enforced given that the key exists. If you've got a field which will or might not exist however should be distinctive once it will, you can combine the distinct possibility with the distributed possibility. If you're acquainted with sparse indexes on relative databases, MongoDB’s sparse indexes square measure a very completely different idea. MongoDB sparse indexes square measure essentially indexes that require not embrace each document as an associate entry.
To create a distributed index, embrace the distributed possibility. as an example, if providing associate email address was ex gratia however, if provided, ought to be distinctive, we tend to might do,
- db.ensureIndex({"email" : 1}, {"unique" : true, "sparse" : true})
Conclusion
In this article, we discuss how to create an index in MongoDB. How it will work and also discuss different types of indexes in MongoDB like Compound Index, Unique Index, Sparse Index. These indexes some normally known as the basic indexes which are quite similar with the out database systems. In the next article, we will discuss some advanced types of the index in the MongoDB.
