Machine Learning: Introduction
Introduction
In the previous chapter, we studied data science, functions, and methods used, and their python implementations.
In this article, we will be studying Machine Learning.
Note: if you can correlate anything with yourself or your life, there are greater chances of understanding the concept. So try to understand everything by relating it to humans.
What is Machine Learning?
Machine learning is the scientific study of algorithms and statistical models that computer systems use to perform a specific task without using explicit instructions, relying on patterns and inference instead. It is seen as a subset of artificial intelligence.
Machine learning is an application of artificial intelligence (AI) that provides systems the ability to automatically learn and improve from experience without being explicitly programmed. Machine learning focuses on the development of computer programs that can access data and use it to learn for themselves.
"A computer program is said to learn from experience E with respect to some class of tasks T and performance measure P, if its performance at tasks in T, as measured by P, improves with experience E."
The meaning of the above statement can be understood as:
In the case of Spam Detection, Task T is detecting a mail as spam or not, Performance measure P is how much mails are correctly detected as spam and Experience E is the number of emails detected as spam and not-a spam. So, if the number of false-positive results decreases continuously on each iteration, then it can be said that the system is learning to classify emails as spam and not-a spam.
Another example could be, Alexa, amazon's NLP service, Task T is to execute the given command, Performance Measure P is the extent to which Alexa is able to "understand" our commands and Experience E is the number of times the given command is executed rightly. So, if Alexa's command execution capabilities improve with time and it is able to develop a better "understanding" of what "humans" means.
How do we do Machine Learning?
I would explain machine learning in layman's terms in the following way,
I dont know how many of you remember the way we were taught A-Z in our kindergarten. For those who dont remember, we were told to, again and again, write A to Z, till the time we were able to recall the name by seeing the diagram of that. In the same way, we train machines, where the machines are given x amount of data points, and the machine tries to form a relationship among those data points, this what I did in my school life, I had a problem learning chemical periodic table so my teacher gave me an algorithm to learn i.e. "LiBeB CNOFNe NaMgAl SiPSClAr", with this I was able to learn 1st eighteen elements in chronological order.
ML algorithms tend to "overfit" data i.e they do not allow any other value to fit into the relationship equation, this is what we do, for example, I had an argument with someone, so its human nature to think that the other person does not understand us or do not want to understand us.
Some Basic Terms
Data Science
Data science is a multi-disciplinary field that uses scientific methods, processes, algorithms, and systems to extract knowledge and insights from structured and unstructured data. Data science is the same concept as data mining and big data: "use the most powerful hardware, the most powerful programming systems, and the most efficient algorithms to solve problems".
Data Mining
- Data mining is the process of discovering patterns in large data sets involving methods at the intersection of machine learning, statistics, and database systems.
- Data mining is an interdisciplinary subfield of computer science and statistics with an overall goal to extract information (with intelligent methods) from a data set and transform the information into a comprehensible structure for further use.
- Data mining is the analysis step of the "knowledge discovery in databases" process or KDD. Aside from the raw analysis step, it also involves database and data management aspects, data pre-processing, model and inference considerations, interestingness metrics, complexity considerations, post-processing of discovered structures, visualization, and online updating
Statistical Learning
- Statistical learning theory is a framework for machine learning drawing from the fields of statistics and functional analysis.
- Statistical learning theory deals with the problem of finding a predictive function based on data.
- Statistical learning theory has led to successful applications in fields such as computer vision, speech recognition, bioinformatics, and baseball.
Knowledge Discovery in Databases(KDD)
- Knowledge discovery describes the process of automatically searching large volumes of data for patterns that can be considered knowledge about the data. It is often described as deriving knowledge from the input data.
- Knowledge discovery developed out of the data mining domain and is closely related to it both in terms of methodology and terminology.
- The most well-known branch of data mining is knowledge discovery, also known as knowledge discovery in databases (KDD). Just as many other forms of knowledge discovery it creates abstractions of the input data.
Which data is converted into information?
The theoretical definition of Information is facts provided or learned about something or someone or we can say data can be said to be informed if it is "useful to me". Information is an abstract term, i.e. for example, if I am a manager and I have to review the work of my team, so the data of work done will become information for me, while on the other hand, this same data may have no value for a person who is not an employee of the same company.
Another example of the same can be you are currently reading this article, the data written in this article is "information" to you, but for a person who dont intends to learn about ML, this is mear data.
So I would conclude by saying "Everything is information and not everything is information".
How can information be converted into knowledge?
The theoretical definition of knowledge is facts, information, and skills acquired through experience or education; the theoretical or practical understanding of a subject or we can say is knowledge is the "information" that we use to transform a "theoretical concept" into "practically feasible product".
For Example, you are currently reading this article, and if you use this "information" to implement it and produce an observable and notable product than this information is said to be converted into knowledge.
For instance, you study linear regression and you used the algorithm to make a classifier that can differentiate between an animal and a human, then that means that you converted your "linear regression" information into "knowledge".
Types of Machine Learning
1. Supervised Learning
When an algorithm learns from example data and associated target responses that can consist of numeric values or string labels, such as classes or tags, in order to later predict the correct response when posed with new examples comes under the category of Supervised learning. This approach is indeed similar to human learning under the supervision of a teacher. The teacher provides good examples for the student to memorize, and the student then derives general rules from these specific examples.
List of Supervised Learning algorithms
| Algorithm Name | Description | Type |
| Linear regression | Finds a way to correlate each feature to the output to help predict future values. | Regression |
| Logistic regression | Extension of linear regression that's used for classification tasks. The output variable 3is binary (e.g., only black or white) rather than continuous (e.g., an infinite list of potential colors) | Classification |
| Decision tree | Highly interpretable classification or regression model that splits data-feature values into branches at decision nodes (e.g., if a feature is a color, each possible color becomes a new branch) until a final decision output is made | Regression Classification |
| Naive Bayes | The Bayesian method is a classification method that makes use of the Bayesian theorem. The theorem updates the prior knowledge of an event with the independent probability of each feature that can affect the event. | Regression Classification |
| Support vector machine | Support Vector Machine, or SVM, is typically used for the classification task. SVM algorithm finds a hyperplane that optimally divided the classes. It is best used with a non-linear solver. | Regression (not very common) Classification |
| Random forest | The algorithm is built upon a decision tree to improve the accuracy drastically. Random forest generates many times simple decision trees and uses the 'majority vote' method to decide on which label to return. For the classification task, the final prediction will be the one with the most vote; while for the regression task, the average prediction of all the trees is the final prediction. | Regression Classification |
| AdaBoost | Classification or regression technique that uses a multitude of models to come up with a decision but weighs them based on their accuracy in predicting the outcome | Regression Classification |
| Gradient-boosting trees | Gradient-boosting trees is a state-of-the-art classification/regression technique. It is focusing on the error committed by the previous trees and tries to correct it. | Regression Classification |
2. Unsupervised Learning
Whereas when an algorithm learns from plain examples without any associated response, leaving to the algorithm to determine the data patterns on its own. This type of algorithm tends to restructure the data into something else, such as new features that may represent a class or a new series of un-correlated values. They are quite useful in providing humans with insights into the meaning of data and new useful inputs to supervised machine learning algorithms.
List of Supervised Learning algorithms
| Algorithm | Description | Type |
| K-means clustering | Puts data into some groups (k) that each contains data with similar characteristics (as determined by the model, not in advance by humans) | Clustering |
| Gaussian mixture model | A generalization of k-means clustering that provides more flexibility in the size and shape of groups (clusters | Clustering |
| Hierarchical clustering | Splits clusters along a hierarchical tree to form a classification system. Can be used for Cluster loyalty-card customer | Clustering |
| Recommender system | Help to define the relevant data for making a recommendation. | Clustering |
| PCA/T-SNE | Mostly used to decrease the dimensionality of the data. The algorithms reduce the number of features to 3 or 4 vectors with the highest variances. | Dimension Reduction |
3. Reinforcement Learning
It is a type of learning, where the labels are not given but the training is done based on the positive and negative feedback i.e. for each, false-positive outcome system gets negative feedback and for a true positive, the system gets positive feedback.
Errors help you learn because they have a penalty added (cost, loss of time, regret, pain, and so on), teaching you that a certain course of action is less likely to succeed than others. An interesting example of reinforcement learning occurs when computers learn to play video games by themselves.
In this case, an application presents the algorithm with examples of specific situations, such as having the gamer stuck in a maze while avoiding an enemy. The application lets the algorithm know the outcome of actions it takes, and learning occurs while trying to avoid what it discovers to be dangerous and to pursue survival.
| Reinforcement Learning | Supervised Learning |
| Reinforcement learning is all about making decisions sequentially. In simple words, we can say that the out depends on the state of the current input and the next input depends on the output of the previous input | In Supervised learning, the decision is made on the initial input or the input given at the start |
| In Reinforcement learning decision is dependent, So we give labels to sequences of dependent decisions | Supervised learning the decisions are independent of each other so labels are given to each decision. |
| Example: Chess game | Example: Object recognition |
Types of Reinforcement Learning
There are two types of Reinforcement:
1. Positive
Advantages of reinforcement learning are:
- Maximizes Performance
- Sustain Change for a long period of time
- Too much Reinforcement can lead to an overload of states which can diminish the results
2. Negative
- Increases Behavior
- Provide defiance to a minimum standard of performance
- It Only provides enough to meet up the minimum behavior
4. Semi-Supervised Learning
Where an incomplete training signal is given: a training set with some (often many) of the target outputs missing. There is a special case of this principle known as Transduction where the entire set of problem instances is known at learning time, except that part of the targets is missing.
Practical Applications of Semi-Supervised Learning
- Protein Sequence Classification: Inferring the function of proteins typically requires active human intervention.
- Web Content Classification: Organizing the knowledge available in billions of web pages will advance different segments of AI. Unfortunately, that task typically requires human intervention to classify the content.
Application of Machine learning
1. Augmentation
2. Automation
3. Finance Industry
4. Government organization
The government makes use of ML to manage public safety and utilities. Take the example of China with massive face recognition. The government uses Artificial intelligence to prevent jaywalker.
5. Healthcare industry
6. Marketing
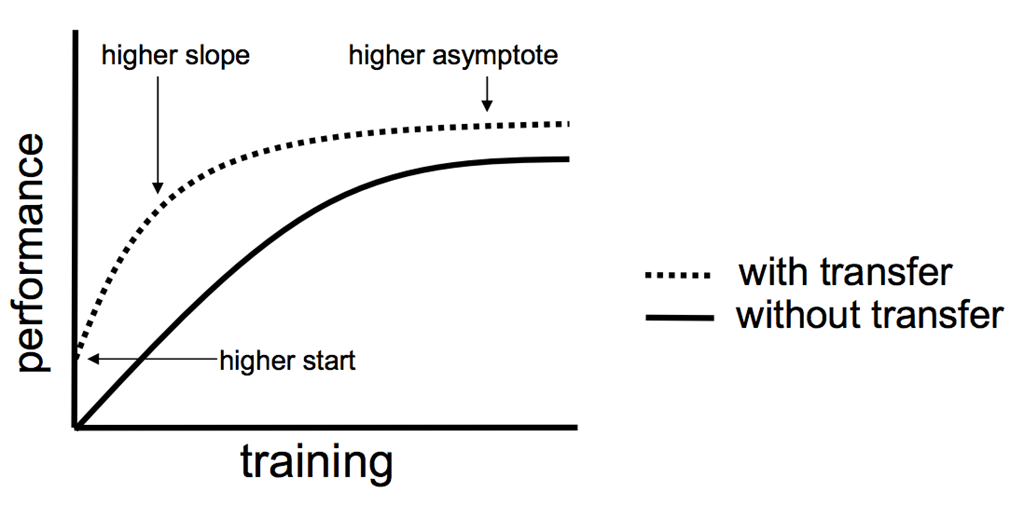
Transfer Learning
Transfer learning is a machine learning method where a model developed for a task is reused as the starting point for a model on a second task.
It is a popular approach in deep learning where pre-trained models are used as the starting point on computer vision and natural language processing tasks given the vast compute and time resources required to develop neural network models on these problems and from the huge jumps in the skill that they provide on related problems.
Two common approaches are as follows:
- Develop a Model Approach
- Pre-trained Model Approach
Types of Machine Learning Algorithms
1. Regression
Regression models are used to predict a continuous value. Predicting prices of a house given the features of house like size, price, etc is one of the common examples of Regression. It is a supervised technique.
- Simple Linear Regression
- Polynomial Regression
- Support Vector Regression
- Decision Tree Regression
- Random Forest Regression
2. Clustering
Clustering is the task of dividing the population or data points into a number of groups such that data points in the same groups are more similar to other data points in the same group and dissimilar to the data points in other groups. It is basically a collection of objects on the basis of similarity and dissimilarity between them. Types:
- K-Means Clustering
- Mean-Shift Clustering
- Density-Based Spatial Clustering of Applications with Noise (DBSCAN)
- Expectation-Maximization (EM) Clustering using Gaussian Mixture Models (GMM)
- Agglomerative Hierarchical Clustering
3. Decision Tree
Decision Tree Analysis is a general, predictive modeling tool that has applications spanning a number of different areas. In general, decision trees are constructed via an algorithmic approach that identifies ways to split a data set based on different conditions. It is one of the most widely used and practical methods for supervised learning. Decision Trees are a non-parametric supervised learning method used for both classification and regression tasks. The goal is to create a model that predicts the value of a target variable by learning simple decision rules inferred from the data features. Types:
- ID3 (Iterative Dichotomiser 3)
- C4.5 (successor of ID3)
- CART (Classification And Regression Tree)
- CHAID (CHi-squared Automatic Interaction Detector). ...
- MARS: extends decision trees to handle numerical data better.
- Conditional Inference Trees.
4. Association Learning Rule
Association rule learning is a rule-based machine learning method for discovering interesting relations between variables in large databases. It is intended to identify strong rules discovered in databases using some measures of interestingness. Association rule mining finds interesting associations and relationships among large sets of data items. This rule shows how frequently an itemset occurs in a transaction. A typical example is a Market Based Analysis. Rules do not tie back a users’ different transactions over time to identify relationships. A list of items with unique transaction IDs (from all users) is studied as one group. This is helpful in the placement of products on aisles.
5. Artificial Neural Network
Artificial neural networks (ANN) or connectionist systems are computing systems that are inspired by, but not identical to, biological neural networks that constitute animal brains. Such systems "learn" to perform tasks by considering examples, generally without being programmed with task-specific rules.
An ANN is based on a collection of connected units or nodes called artificial neurons, which loosely model the neurons in a biological brain. Each connection, like the synapses in a biological brain, can transmit a signal to other neurons. An artificial neuron that receives a signal then processes it and can signal neurons connected to it.
For example, in image recognition, they might learn to identify images that contain cats by analyzing example images that have been manually labeled as "cat" or "no cat" and using the results to identify cats in other images.
6. Induction Logic Programming
Inductive Logic Programming (ILP), is a subfield of machine learning that learns computer programs from data, where the programs and data are logic programs. It may also be explained as a form of supervised machine learning which uses logic programming (primarily Prolog) as a uniform representation for background knowledge, examples, and induced theories. ILP is preferred over other machine learning approaches because of its easy comprehensibility, intelligibility, and ability to include additional information in the learning problem.
7. Support Vector Machine
Support Vector Machine (SVM) is a supervised machine learning algorithm that can be used for both classification or regression challenges. However, it is mostly used in classification problems. In this algorithm, we plot each data item as a point in n-dimensional space (where n is the number of features you have) with the value of each feature being the value of a particular coordinate. Then, we perform classification by finding the hyper-plane that differentiates the two classes very well.
8. Similarity and Metric Learning
Similarity learning is an area of supervised machine learning in artificial intelligence. It is closely related to regression and classification, but the goal is to learn from a similarity function that measures how similar or related two objects are. It has applications in the ranking, in recommendation systems, visual identity tracking, face verification, and speaker verification.
Metric learning is the task of learning a distance function over objects. A metric or distance function has to obey four axioms: non-negativity, the identity of indiscernibles, symmetry, and subadditivity (or the triangle inequality).
9. Bayesian Networks
Bayesian inference is a method of statistical inference in which Bayes' theorem is used to update the probability for a hypothesis as more evidence or information becomes available. Bayesian inference is an important technique in statistics, and especially in mathematical statistics. Bayesian learning treats model parameters as random variables
10. Representation Learning
In machine learning, feature learning, or representation learning[1] is a set of techniques that allows a system to automatically discover the representations needed for feature detection or classification from raw data. This replaces manual feature engineering and allows a machine to both learn the features and use them to perform a specific task.
Feature learning is motivated by the fact that machine learning tasks such as classification often require input that is mathematically and computationally convenient to process.
11. Sparse Matrix Learning
A sparse matrix is a matrix that is comprised of mostly zero values. Sparse matrices are distinct from matrices with mostly non-zero values, which are referred to as dense matrices. This type of learning is mostly done for optimization in machine learning.
Conclusion
In this chapter, we studied machine learning and some key terms associated with it.
From the next chapter onwards, we will start implementing machine learning algorithms.
Author

Rohit Gupta
13
60.4k
3.2m