Machine Learning: Logistic Regression
Introduction
In the previous chapter, we studied Linear Regression.
Note: if you can correlate anything with yourself or your life, there are greater chances of understanding the concept. So try to understand everything by relating it to humans.
What is Logistic Regression?
Logistic regression is the appropriate regression analysis to conduct when the dependent variable is dichotomous (binary). Like all regression analyses, logistic regression is a predictive analysis. Logistic regression is used to describe data and to explain the relationship between one dependent binary variable and one or more nominal, ordinal, interval or ratio-level independent variables. Logistic regression models the probabilities for classification problems with two possible outcomes. It’s an extension of the linear regression model for classification problems.
What is it used for?
Logistic regression is used to describe data and to explain the relationship between one dependent binary variable and one or more nominal, ordinal, interval, or ratio-level independent variables.
Difference between Linear and Logistic Regression
| BASIS FOR COMPARISON | LINEAR REGRESSION | LOGISTIC REGRESSION |
| Basic | The data is modeled using a straight line. | The probability of some obtained event is represented as a linear function of a combination of predictor variables. |
| Linear relationship between the dependent and independent variables | Is required | Not required |
| The independent variable | Could be correlated with each other. (Especially in multiple linear regression) | Should not be correlated with each other (no multicollinearity exists). |
| Outcome | the outcome (dependent variable) is continuous. It can have any one of an infinite number of possible values. |
the outcome (dependent variable) has only a limited number of possible values. |
| Dependent Variable | Linear regression is used when your response variable is continuous. For instance, weight, height, number of hours, etc. |
Logistic regression is used when the response variable is categorical in nature. For instance, yes/no, true/false, red/green/blue, 1st/2nd/3rd/4th, etc. |
| Equation | Linear regression gives an equation that is of the form Y = MX + C, which means equation with degree 1. |
logistic regression gives an equation which is of the form Y = eX + e-X |
| Coefficient Interpretation | the coefficient interpretation of independent variables is quite straightforward (i.e. holding all other variables constant, with a unit increase in this variable, the dependent variable is expected to increase/decrease by xxx). |
depends on the family (binomial, Poisson, etc.) and link (log, logit, inverse-log, etc.) you use, the interpretation is different. |
| Error Minimization Technique | uses ordinary least squares method to minimize the errors and arrive at a best possible fit |
uses a maximum likelihood method to arrive at the solution. |
Why is Logistic Regression called so?
The meaning of the term regression is very simple: any process that attempts to find relationships between variables is called regression. Logistic regression is a regression because it finds relationships between variables. It is logistic because it uses a logistic function as a link function. Hence the full name.
What is the goal of Logistic Regression?
The goal of logistic regression is to correctly predict the category of outcome for individual cases using the most parsimonious model. To accomplish this goal, a model is created that includes all predictor variables that are useful in predicting the response variable. In other words, The goal of logistic regression is to find the best fitting (yet biologically reasonable) model to describe the relationship between the dichotomous characteristic of interest (dependent variable = response or outcome variable) and a set of independent (predictor or explanatory) variables.
Types of Logistic Regression
1. Binary Logistic Regression
The categorical response has only two 2 possible outcomes. Example: Spam or Not
2. Multinomial Logistic Regression
Three or more categories without ordering. Example: Predicting which food is preferred more (Veg, Non-Veg, Vegan)
3. Ordinal Logistic Regression
Three or more categories with ordering. Example: Movie rating from 1 to 5
Key Terms
1. Logit
In statistics, the logit function or the log-odds is the logarithm of the odds p/(1 − p) where p is the probability. It is a type of function that creates a map of probability values from [0,1] to It is the inverse of the sigmoidal "logistic" function or logistic transform used in mathematics, especially in statistics.
 It is the inverse of the sigmoidal "logistic" function or logistic transform used in mathematics, especially in statistics.
It is the inverse of the sigmoidal "logistic" function or logistic transform used in mathematics, especially in statistics.In deep learning, the term logits layer is popularly used for the last neuron layer of neural networks used for classification tasks, which produce raw prediction values as real numbers ranging from .
2. Logistic Function
The logistic function is a sigmoid function, which takes any real input t, (), and outputs a value between zero and one; for the logit, this is interpreted as taking input log-odds and having output probability. The standard logistic function is defined as follows:
 ), and outputs a value between zero and one; for the logit, this is interpreted as taking input log-odds and having output probability. The standard logistic function
), and outputs a value between zero and one; for the logit, this is interpreted as taking input log-odds and having output probability. The standard logistic function  is defined as follows:
is defined as follows:
3. Inverse of Logistic Function
We can now define the logit (log odds) function as the inverse of the standard logistic function. It is easy to see that it satisfies:
 of the standard logistic function. It is easy to see that it satisfies:
of the standard logistic function. It is easy to see that it satisfies:
and equivalently, after exponentiating both sides we have the odds:

where,
- g is the logit function. The equation for g(p(x)) illustrates that the logit (i.e., log-odds or natural logarithm of the odds) is equivalent to the linear regression expression.
- ln denotes the natural logarithm.
- The formula for p(x) illustrates that the probability of the dependent variable for a given case is equal to the value of the logistic function of the linear regression expression. This is important as it shows that the value of the linear regression expression can vary from negative to positive infinity and yet, after transformation, the resulting probability p(x) ranges between 0 and 1.
- is the intercept from the linear regression equation (the value of the criterion when the predictor is equal to zero).
- is the regression coefficient multiplied by some value of the predictor.
- base 'e' denotes the exponential function.
 is the intercept from the linear regression equation (the value of the criterion when the predictor is equal to zero).
is the intercept from the linear regression equation (the value of the criterion when the predictor is equal to zero). is the regression coefficient multiplied by some value of the predictor.
is the regression coefficient multiplied by some value of the predictor.4. Odds
The odds of the dependent variable equaling a case (given some linear combination x of the predictors) is equivalent to the exponential function of the linear regression expression. This illustrates how the logit serves as a link function between the probability and the linear regression expression. Given that the logit ranges between negative and positive infinity, it provides an adequate criterion upon which to conduct linear regression and the logit is easily converted back into the odds.
So we define odds of the dependent variable equaling a case (given some linear combination x of the predictors) as follows:

5. Odds Ration
For a continuous independent variable, the odds ratio can be defined as:

This exponential relationship provides an interpretation for : The odds multiply by for every 1-unit increase in x.
 : The odds multiply by
: The odds multiply by  for every 1-unit increase in x.
for every 1-unit increase in x.For a binary independent variable, the odds ratio is defined as where a, b, c, and d are cells in a 2×2 contingency table.
 where a, b, c, and d are cells in a 2×2 contingency table.
where a, b, c, and d are cells in a 2×2 contingency table.6. Multiple Explanatory Variable
If there are multiple explanatory variables, the above expression can be revised to
 can be revised to
can be revised to
Then when this is used in the equation relating the log odds of success to the values of the predictors, the linear regression will be a multiple regression with m explanators; the parameters for all j = 0, 1, 2, ..., m are all estimated.
 for all j = 0, 1, 2, ..., m are all estimated.
for all j = 0, 1, 2, ..., m are all estimated.Again, the more traditional equations are:

and

where usually b = e.
Logistic Regression
logistic regression produces a logistic curve, which is limited to values between 0 and 1. Logistic regression is similar to linear regression, but the curve is constructed using the natural logarithm of the “odds” of the target variable, rather than the probability. Moreover, the predictors do not have to be normally distributed or have equal variance in each group.
The logistic Regression Equation is given by

Taking natural log on both sides we get

Till now, we have seen the equation for one variable, so now following is the equation when the number of variables is more than one
where usually b = e. OR
Linear regression will fail in cases where the boundaries are pre-defined, as if we use Linear Regression, it may predict outside the boundaries. For example, let's take the example of housing price prediction, that we used in the last chapter, so when predicting, there are chances that linear regression would predict the price too high, which may not be practically possible, or too loss such as may be negative.
Since in the case of binary classification, there are only two possible outcomes, but it is not necessary that the input data be distributed uniformly, it is often seen that the class '0' data point if found in the decision boundary of class '1'. Since, the sigmoid function is a curve, the possibility of getting a perfect fit increases, hence resolving the problem of having
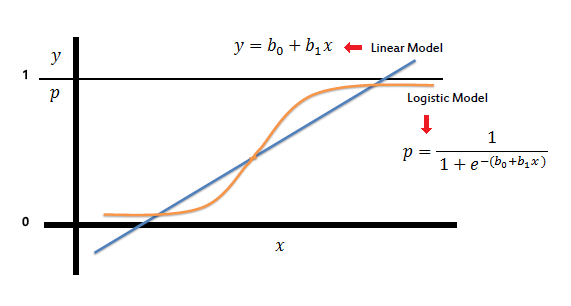
Logistic Regression Example
Let's take the example of the IRIS dataset, you can directly import it from the sklearn dataset repository. Feel free to use any dataset, there some very good datasets available on kaggle and with Google Colab.
1. Using SKLearn
- %matplotlib inline
- import numpy as np
- import matplotlib.pyplot as plt
- import seaborn as sns
- from sklearn import datasets
- from sklearn.linear_model import LogisticRegression
In the above code, we are importing the required libraries, that we will be using.
- iris = datasets.load_iris()
- X = iris.data[:, :2]
- y = (iris.target != 0) * 1
- plt.figure(figsize=(10, 6))
- plt.scatter(X[y == 0][:, 0], X[y == 0][:, 1], color='b', label='0')
- plt.scatter(X[y == 1][:, 0], X[y == 1][:, 1], color='r', label='1')
- plt.legend();
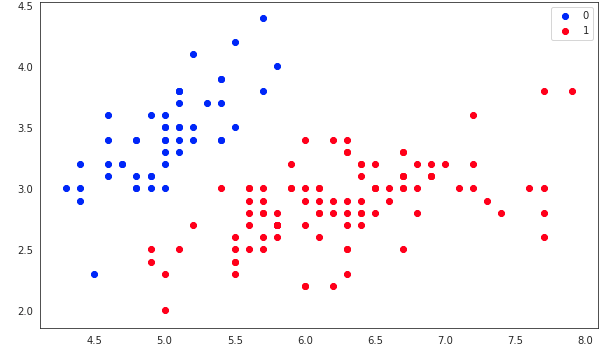
- model = LogisticRegression(C=1e2)
- %time model.fit(X, y)
- print(model.intercept_, model.coef_,model.n_iter_)
The output that I got for training is:
CPU times: user 2.45 ms, sys: 1.06 ms, total: 3.51 ms Wall time: 1.76 ms
model.itercept: [-33.08987216]
model.coeffiecent: [[ 14.75218964 -14.87575477]]
number of iterations: [12]
- plt.figure(figsize=(10, 6))
- plt.scatter(X[y == 0][:, 0], X[y == 0][:, 1], color='b', label='0')
- plt.scatter(X[y == 1][:, 0], X[y == 1][:, 1], color='r', label='1')
- plt.legend()
- x1_min, x1_max = X[:,0].min(), X[:,0].max(),
- x2_min, x2_max = X[:,1].min(), X[:,1].max(),
- xx1, xx2 = np.meshgrid(np.linspace(x1_min, x1_max), np.linspace(x2_min, x2_max))
- grid = np.c_[xx1.ravel(), xx2.ravel()]
- probs = model.predict(grid).reshape(xx1.shape)
- plt.contour(xx1, xx2, probs, [0.5], linewidths=1, colors='black');
The above code, lets us visulaize the regression line with respect to the input data.
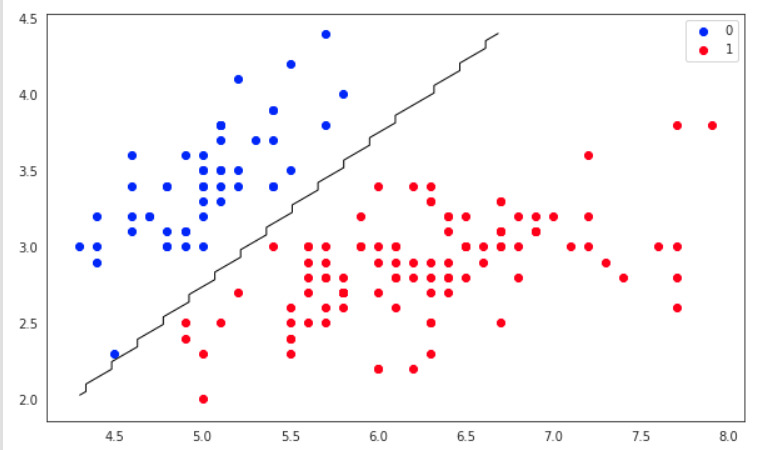
- pred = model.predict(X[1:2])
- print(pred)
LR_Sklearn.py
- %matplotlib inline
- import numpy as np
- import matplotlib.pyplot as plt
- import seaborn as sns
- from sklearn import datasets
- from sklearn.linear_model import LogisticRegression
- iris = datasets.load_iris()
- X = iris.data[:, :2]
- y = (iris.target != 0) * 1
- plt.figure(figsize=(10, 6))
- plt.scatter(X[y == 0][:, 0], X[y == 0][:, 1], color='b', label='0')
- plt.scatter(X[y == 1][:, 0], X[y == 1][:, 1], color='r', label='1')
- plt.legend();
- model = LogisticRegression(C=1e2)
- %time model.fit(X, y)
- print(model.intercept_, model.coef_,model.n_iter_)
- plt.figure(figsize=(10, 6))
- plt.scatter(X[y == 0][:, 0], X[y == 0][:, 1], color='b', label='0')
- plt.scatter(X[y == 1][:, 0], X[y == 1][:, 1], color='r', label='1')
- plt.legend()
- x1_min, x1_max = X[:,0].min(), X[:,0].max(),
- x2_min, x2_max = X[:,1].min(), X[:,1].max(),
- xx1, xx2 = np.meshgrid(np.linspace(x1_min, x1_max), np.linspace(x2_min, x2_max))
- grid = np.c_[xx1.ravel(), xx2.ravel()]
- probs = model.predict(grid).reshape(xx1.shape)
- plt.contour(xx1, xx2, probs, [0.5], linewidths=1, colors='black');
2. Using Numpy
- %matplotlib inline
- import numpy as np
- import matplotlib.pyplot as plt
- import seaborn as sns
- from sklearn import datasets a
In the above code, we are importing the required libraries, that we will be using.
- iris = datasets.load_iris()
- X = iris.data[:, :2]
- y = (iris.target != 0) * 1
- plt.figure(figsize=(10, 6))
- plt.scatter(X[y == 0][:, 0], X[y == 0][:, 1], color='b', label='0')
- plt.scatter(X[y == 1][:, 0], X[y == 1][:, 1], color='r', label='1')
- plt.legend();
- class LogisticRegression:
- def __init__(self, lr=0.01, num_iter=100000, fit_intercept=True, verbose=False):
- self.lr = lr
- self.num_iter = num_iter
- self.fit_intercept = fit_intercept
- self.verbose = verbose
- def __add_intercept(self, X):
- intercept = np.ones((X.shape[0], 1))
- return np.concatenate((intercept, X), axis=1)
- def __sigmoid(self, z):
- return 1 / (1 + np.exp(-z))
- def __loss(self, h, y):
- return (-y * np.log(h) - (1 - y) * np.log(1 - h)).mean()
- def fit(self, X, y):
- if self.fit_intercept:
- X = self.__add_intercept(X)
- # weights initialization
- self.theta = np.zeros(X.shape[1])
- for i in range(self.num_iter):
- z = np.dot(X, self.theta)
- h = self.__sigmoid(z)
- gradient = np.dot(X.T, (h - y)) / y.size
- self.theta -= self.lr * gradient
- z = np.dot(X, self.theta)
- h = self.__sigmoid(z)
- loss = self.__loss(h, y)
- if(self.verbose ==True and i % 10000 == 0):
- print(f'loss: {loss} \t')
- def predict_prob(self, X):
- if self.fit_intercept:
- X = self.__add_intercept(X)
- return self.__sigmoid(np.dot(X, self.theta))
- def predict(self, X):
- return self.predict_prob(X).round()
- __init__ - constructor to initialize all the required variables with default values or initial values
- __add_intercept - to find the model intercept value
- __sigmoid - function to return sigmoid curve
- __loss - function to return loss
- fit - function to calculate and return the regression line
- predict_prob - helper function used for prediction
- predict - function to return predicted value
- model = LogisticRegression(lr=0.1, num_iter=3000)
- %time model.fit(X, y)
- preds = model.predict(X[1:2])
- print(preds)
- print(model.theta)
Parameter values of my model are :
[-1.44894305 4.25546329 -6.89489245]
- plt.figure(figsize=(10, 6))
- plt.scatter(X[y == 0][:, 0], X[y == 0][:, 1], color='b', label='0')
- plt.scatter(X[y == 1][:, 0], X[y == 1][:, 1], color='r', label='1')
- plt.legend()
- x1_min, x1_max = X[:,0].min(), X[:,0].max(),
- x2_min, x2_max = X[:,1].min(), X[:,1].max(),
- xx1, xx2 = np.meshgrid(np.linspace(x1_min, x1_max), np.linspace(x2_min, x2_max))
- grid = np.c_[xx1.ravel(), xx2.ravel()]
- probs = model.predict_prob(grid).reshape(xx1.shape)
- plt.contour(xx1, xx2, probs, [0.5], linewidths=1, colors='black');
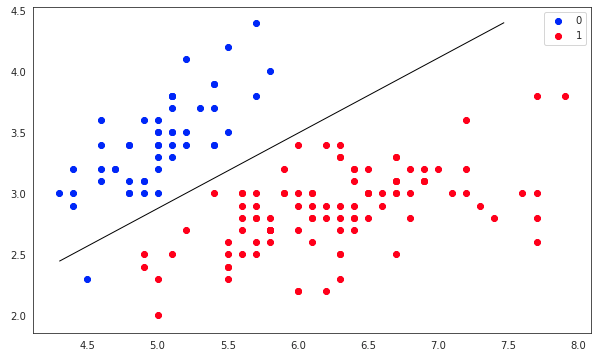
LR_NumPy.py
- %matplotlib inline
- import numpy as np
- import matplotlib.pyplot as plt
- import seaborn as sns
- from sklearn import datasets
- iris = datasets.load_iris()
- X = iris.data[:, :2]
- y = (iris.target != 0) * 1
- plt.figure(figsize=(10, 6))
- plt.scatter(X[y == 0][:, 0], X[y == 0][:, 1], color='b', label='0')
- plt.scatter(X[y == 1][:, 0], X[y == 1][:, 1], color='r', label='1')
- plt.legend();
- class LogisticRegression:
- def __init__(self, lr=0.01, num_iter=100000, fit_intercept=True, verbose=False):
- self.lr = lr
- self.num_iter = num_iter
- self.fit_intercept = fit_intercept
- self.verbose = verbose
- def __add_intercept(self, X):
- intercept = np.ones((X.shape[0], 1))
- return np.concatenate((intercept, X), axis=1)
- def __sigmoid(self, z):
- return 1 / (1 + np.exp(-z))
- def __loss(self, h, y):
- return (-y * np.log(h) - (1 - y) * np.log(1 - h)).mean()
- def fit(self, X, y):
- if self.fit_intercept:
- X = self.__add_intercept(X)
- # weights initialization
- self.theta = np.zeros(X.shape[1])
- for i in range(self.num_iter):
- z = np.dot(X, self.theta)
- h = self.__sigmoid(z)
- gradient = np.dot(X.T, (h - y)) / y.size
- self.theta -= self.lr * gradient
- z = np.dot(X, self.theta)
- h = self.__sigmoid(z)
- loss = self.__loss(h, y)
- if(self.verbose ==True and i % 10000 == 0):
- print(f'loss: {loss} \t')
- def predict_prob(self, X):
- if self.fit_intercept:
- X = self.__add_intercept(X)
- return self.__sigmoid(np.dot(X, self.theta))
- def predict(self, X):
- return self.predict_prob(X).round()
- model = LogisticRegression(lr=0.1, num_iter=3000)
- %time model.fit(X, y)
- preds = model.predict(X[1:2])
- print(preds)
- print(model.theta)
- plt.figure(figsize=(10, 6))
- plt.scatter(X[y == 0][:, 0], X[y == 0][:, 1], color='b', label='0')
- plt.scatter(X[y == 1][:, 0], X[y == 1][:, 1], color='r', label='1')
- plt.legend()
- x1_min, x1_max = X[:,0].min(), X[:,0].max(),
- x2_min, x2_max = X[:,1].min(), X[:,1].max(),
- xx1, xx2 = np.meshgrid(np.linspace(x1_min, x1_max), np.linspace(x2_min, x2_max))
- grid = np.c_[xx1.ravel(), xx2.ravel()]
- probs = model.predict_prob(grid).reshape(xx1.shape)
- plt.contour(xx1, xx2, probs, [0.5], linewidths=1, colors='black');
3. Using TensorFlow
- from __future__ import print_function
- import tensorflow as tf
- # Import MNIST data
- from tensorflow.examples.tutorials.mnist import input_data
- mnist = input_data.read_data_sets("/tmp/data/", one_hot=True)
- # Parameters
- learning_rate = 0.01
- training_epochs = 100
- batch_size = 100
- display_step = 50
- # tf Graph Input
- x = tf.placeholder(tf.float32, [None, 784]) # mnist data image of shape 28*28=784
- y = tf.placeholder(tf.float32, [None, 10]) # 0-9 digits recognition => 10 classes
- # Set model weights
- W = tf.Variable(tf.zeros([784, 10]))
- b = tf.Variable(tf.zeros([10]))
Here we are setting X and Y as the actual training data and the W and b as the trainable data, where:
- W means Weight
- b means bais
- X means the dependent variable
- Y means the independent variable
- # Construct model
- pred = tf.nn.softmax(tf.matmul(x, W) + b) # Softmax
- # Minimize error using cross entropy
- cost = tf.reduce_mean(-tf.reduce_sum(y*tf.log(pred), reduction_indices=1))
- # Gradient Descent
- optimizer = tf.train.GradientDescentOptimizer(learning_rate).minimize(cost)
- # Initialize the variables (i.e. assign their default value)
- init = tf.global_variables_initializer()
In the above code, we are
- setting the model using the Softmax method
- cost calculation will be based on the reduced mean method
- the optimizer is chosen to be Gradient Descent which minimizes cost
- the variable initializer is chosen to be a global variable initializer
- # Start training
- with tf.Session() as sess:
- # Run the initializer
- sess.run(init)
- # Training cycle
- for epoch in range(training_epochs):
- avg_cost = 0.
- total_batch = int(mnist.train.num_examples/batch_size)
- # Loop over all batches
- for i in range(total_batch):
- batch_xs, batch_ys = mnist.train.next_batch(batch_size)
- # Run optimization op (backprop) and cost op (to get loss value)
- _, c = sess.run([optimizer, cost], feed_dict={x: batch_xs,
- y: batch_ys})
- # Compute average loss
- avg_cost += c / total_batch
- # Display logs per epoch step
- if (epoch+1) % display_step == 0:
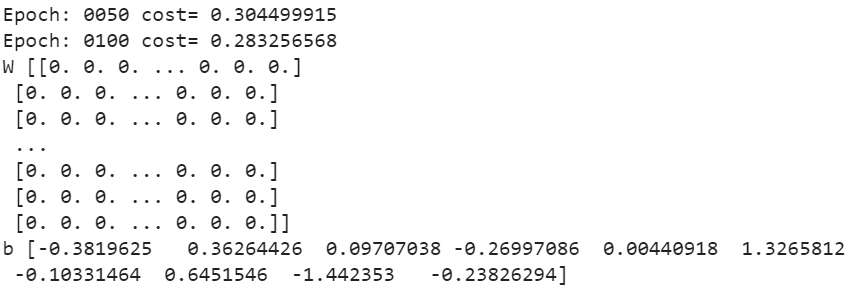
- print("Epoch:", '%04d' % (epoch+1), "cost=", "{:.9f}".format(avg_cost))
- training_cost = sess.run(cost, feed_dict ={x: batch_xs,
- y: batch_ys})
- weight = sess.run(W)
- bias = sess.run(b)
- print("W",weight,"\nb",bias)
- eq= tf.math.sigmoid((tf.matmul(x, weight) + bias))
LR_tensorflow.py
- from __future__ import print_function
- import tensorflow as tf
- # Import MNIST data
- from tensorflow.examples.tutorials.mnist import input_data
- mnist = input_data.read_data_sets("/tmp/data/", one_hot=True)
- # Parameters
- learning_rate = 0.01
- training_epochs = 100
- batch_size = 100
- display_step = 50
- # tf Graph Input
- x = tf.placeholder(tf.float32, [None, 784]) # mnist data image of shape 28*28=784
- y = tf.placeholder(tf.float32, [None, 10]) # 0-9 digits recognition => 10 classes
- # Set model weights
- W = tf.Variable(tf.zeros([784, 10]))
- b = tf.Variable(tf.zeros([10]))
- # Construct model
- pred = tf.nn.softmax(tf.matmul(x, W) + b) # Softmax
- # Minimize error using cross entropy
- cost = tf.reduce_mean(-tf.reduce_sum(y*tf.log(pred), reduction_indices=1))
- # Gradient Descent
- optimizer = tf.train.GradientDescentOptimizer(learning_rate).minimize(cost)
- # Initialize the variables (i.e. assign their default value)
- init = tf.global_variables_initializer()
- # Start training
- with tf.Session() as sess:
- # Run the initializer
- sess.run(init)
- # Training cycle
- for epoch in range(training_epochs):
- avg_cost = 0.
- total_batch = int(mnist.train.num_examples/batch_size)
- # Loop over all batches
- for i in range(total_batch):
- batch_xs, batch_ys = mnist.train.next_batch(batch_size)
- # Run optimization op (backprop) and cost op (to get loss value)
- _, c = sess.run([optimizer, cost], feed_dict={x: batch_xs,
- y: batch_ys})
- &nbstsp; # Compute average loss
- avg_cost += c / total_batch
- # Display logs per epoch step
- if (epoch+1) % display_step == 0:
- print("Epoch:", '%04d' % (epoch+1), "cost=", "{:.9f}".format(avg_cost))
- training_cost = sess.run(cost, feed_dict ={x: batch_xs,
- y: batch_ys})
- weight = sess.run(W)
- bias = sess.run(b)
- print("W",weight,"\nb",bias)
- eq= tf.math.sigmoid((tf.matmul(x, weight) + bias))
Conclusion
In this chapter, we studied simple logistic regression.
In the next chapter, we will learn about Multiple Linear Regression.
Author

Rohit Gupta
13
61k
3.2m